As promised here is my continuing post on Test Coverage.
More on Test Coverage…
Last post, I wrote about how developers can evaluate their code coverage and overall code quality using their development tools. This post covers how the test team becomes involved more directly. Specifically we will focus on.
- Test coverage workflow
- Test case coverage evaluation
Test Coverage Workflow
The test coverage process can help evaluate and improve the quality of the test execution. This will work for automated acceptance tests, UI test automation, manual testing or even performance and load testing. In figure 1 we address coverage processes for Java and .net code coverage, database permutation coverage, and resource utilization.
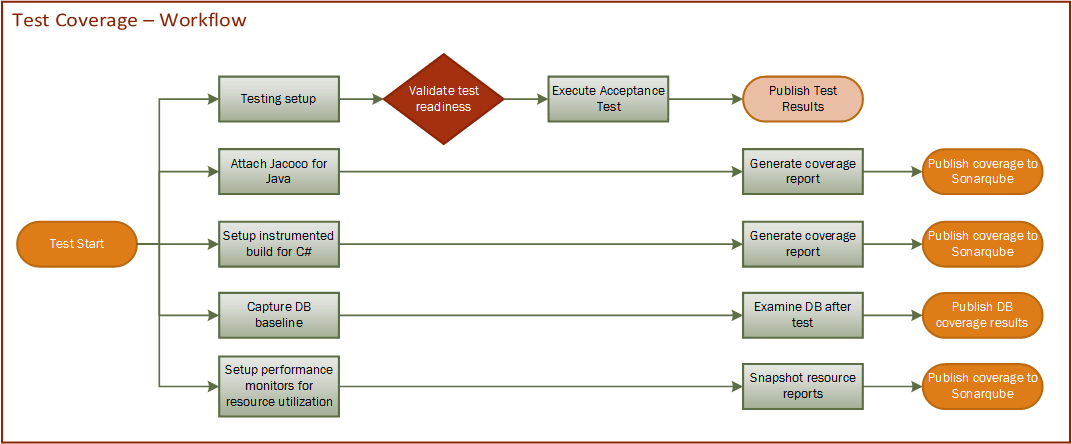
Figure 1
All of the coverage analysis processes follow a similar pattern where the test engineering team sets up tools before and after a test execution. All of these tools and practices should be automated to improve repeatability and reliability of the data generated. This is a core concept of Continuous Delivery, right?
Java code coverage: Jacoco is the current leader in Java code coverage since it does not require instrumentation. Instead it examines the JVM. Additionally this solution has the most current support in the Open Source community.
.Net code coverage: Microsoft provides a number of rich options for coverage and performance for any programs developed within its tool suite. One simple pattern for unmanaged code is to create a test or debug version of the application that includes the instrumentation. For production releases this extra overhead can be removed. There are many articles and examples of how to do this in the online documentation and books available from Microsoft itself.
If you are testing a managed application which means it was developed with the .Net framework, then the instrumentation solution is built right into the runtime engine. So all you need to do is enable the monitoring and recording.
Database coverage: The best solution for database coverage solution depends upon the complexity of the solution under test. For simple database solutions your data team can easily compare the difference. But for best coverage we recommend Grid Tools Coverage analysis solution. This robust tool demands an article on its own. Suffice it to say that it can determine boundary conditions, one to many set conditions as well as pairwise analyses. These concepts help find the critical gaps in test data that are way beyond the usage of production data.
Test Case Coverage Evaluation
Software development in most any form requires a logical model and an implementation in code. The best developers can find the re-usable patterns or code within a complex system to minimize their work. Functional testing gurus also use this pattern for success.
Functional testing is a complicated job. Since software and the connecting solutions can really do anything the mind can imagine, a functional tester must simplify the problem space.
Requirement Pairing – Risks
One risky approach for functional test coverage is to correlate a test case for every use case or requirement. This places the onus upon some other team to create the ‘whole and perfect’ set of requirements. Even if the use cases are very well constructed the functional coverage is limited to the top level design. This type of testing will miss many of the permutations.
Output Focused Coverage without Input Analysis
Code coverage tools will yield a ‘code coverage’ of the functional test suite. This clearly measurable technique has significant merit, but a few problems. Since the process only measures the results, the test input pattern could be spaghetti. Any resulting data would not help improve the coverage efficiently. It needs a complementary practice on the front end to assist the test team. Another obvious gap in code coverage is where the database and requirements analysis concepts shine. If the developer does not write code to address a particular permutation then it will not show up as missing during code coverage.
Model Based Coverage
Orasi recommends the new test modeling solution from our partner Grid-Tools which leverages one of the simplest modelling techniques in Computer Science. Using the flowchart to describe a system under test is a touch of genius. By laying out a UI or application in Agile Designer, a test engineer quantifies the permutations of nodes and paths. Then the tool will generate an optimized set of cases to reduce the actual test cases from the full set of permutations to one that covers all the nodes and/or paths. Furthermore the model helps drive to a state machine driven evaluation of the system under test which pushes the focus away from ad hoc test case development.
Models can become complex but they are inherently simpler than an alphabetical or chronological list of test cases. Challenging the test team to develop and maintain a clarifying model of the system under test is also a great checkpoint for the overall project complexity. Too often test plans are boilerplate documents that are created and never re-used. By making the actual test plans into a living model that generates the test cases the scrum masters and testers can insure that the regression processes are complete.
Designing Test Automation from a Model
Another way to win with this modeling technique is to logically prioritize test automation efforts. After the test cases are quantified you can more easily develop an automation strategy based on planned labor savings. Furthermore, a clean model will simplify the development required to do the test automation. Any test automation without a clear model of the application is illogical.
Adding Data Permutations
When applications are data driven the permutations are not easily enumerated within a flow chart. However this is actually the real value in the AD tool. Since it is part of the Test Data Management suite of tools it accepts data values in the nodes. This is very empowering in several ways. First the data pools can be updated without having to change the flow chart models. This allows a group that is focused upon the data to collaborate more effectively with the functional test teams who own the flow charts.
The test data team can create scripts directly within the database to create the data. They can create the best possible data by analyzing the data in production. They can also look at the actual data types within the database to find boundary, edge and error conditions to provide the best test coverage of the RDMS constraints and connecting logic.
When you reach this point you are really changing the game. This connects functional coverage with underlying data coverage to achieve a very high rate of coverage during integration validation.
By David Guimbellot, Area VP of Continuous Delivery & Test Data Management at Orasi Software