As part of a workshop discussion someone posed the following example to our group of test professionals and asked how we would solve the following problems. I am paraphrasing.
- How do we insure data quality and integrity at the application programming interface (API) level in the new data warehouse? Note that the solution below is a web-service-based query API against a centralized data warehouse. This is replacing some queries that were going against the source systems more directly.
- How do we improve the reliability of the test automation against this solution? The current test automation was a suite of web API tests against a feed of production data.
- How do we adapt to the large amount of ETL scripts that digest data from a broad range of source systems? The scripts were designed based upon reporting and query requirements. Many of the source data systems were legacy solutions such as mainframes that could not be modified. The quality assurance (QA) team was not part of the design process.
- How do we adapt to the high rate of change in many of the data types? The system was expanding organically as the business needs were coming more directly from the end users in an agile-like process.
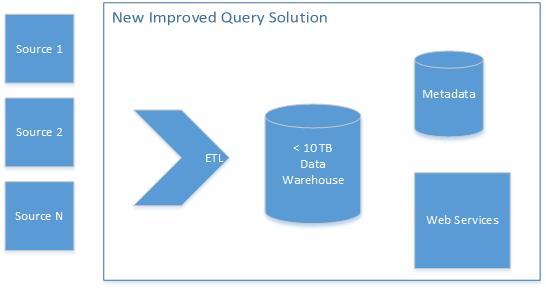
One of the first and best suggestions came from someone who had worked on a similar solution. Her idea was to create TEST_ETL script that could validate that the ETL process itself was working. I liked this, because it injected a validation checkpoint that could be used both during test and production. She further suggested that the solution should have custom validation that was aware of the data and the data warehouse design. This was really heading the solution in the right direction. However, due to the complexity of the inputs and the underlying data warehouse, this could be a big challenge without “source”-level access. The traditional testers balked at this level of engineering. The following diagram shows this extension.
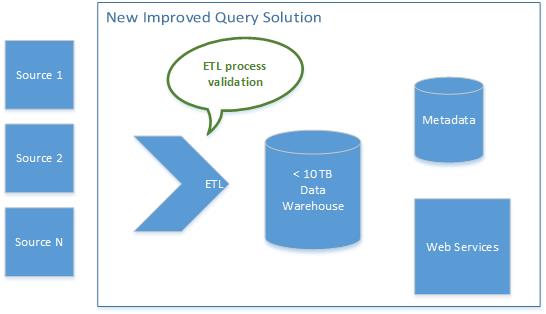
Data-Centric Quality Engineering
At the outset, one of the challenges inherent in data quality is that the solution team must dig into the actual data schema, flow, and design with database- and data-warehouse-specific tools. Without a data focus, the software testing would observe the solution as procedural software. This quality process would only assure the quality of the web services API which is really just a shim on top of the data warehouse design.
Philosophically, the QA team must support the design and development effort to reduce the risk to the project. In most cases, the easiest way to plan QA resources is to assign them to the areas of change or customization in direct proportion. So if the web service API was four weeks out of the 200 weeks in the project, this should be 2% of the QA effort. One quick caveat is that the web services do provide a very low cost and repeatable framework for high-rate test automation. Creating this automation framework is very easy to do and should not take more than a few days. The clear risk of an API-only focus is the gap in validation of the actual results outside of the response latency, errors, assertion faults, or unhandled exceptions.
From the development perspective, the most complex part of the solution is designing the metadata, building the ETL scripts, and laying out the cubes in the data warehouse. How can the test organization support this effort?
Repeatable and Trustworthy Data
The testing team should support this by providing a repeatable and trustworthy set of input data for the ETL processes.
Along one path, the test data should cover the boundary conditions and establish a breadth and depth of coverage to find the errors prior to production. This can be done with a suite of synthetic data generated by scripts.
In order to do this, the delivery team must inspect the existing data model to develop the data generation scripts. We would do this with our Grid-Tools solution which has direct access to the schema, and we could then leverage the deep library of data generation functions already available. This would lead to reusable data pools. In practice, this team would work closely with the data designers to create a suite of test data before they design the actual metadata and ETL scripts. The testing team then becomes responsible for managing the tools and automation process which generates the trustworthy and repeatable test engine.
In addition, the quality process must create more robust forms of automated validation using the data warehouse tools which are available to them. This solution could be used both for development and production support. If the report data are of critical quality then the team should design a robust reconciliation report that can be run periodically against the source systems to validate input results. In some scenarios, the team should use data reconciliation tools and practices (https://en.wikipedia.org/wiki/Data_validation_and_reconciliation).
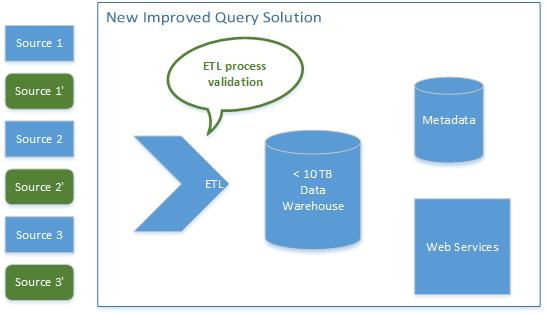
In parallel, they can clone the river of input data. This is a great way to validate end-to-end testing and potential changes to the underlying solution. These tests must occur in balance with the purely synthetic data stream. This is expressed in the diagram above as the source and source prime input elements.
Rollback to Known State
The data warehouse and metabase should be filled with data that generate known good results and ideally can be reset back to a GOLD or SAFE copy. Without this rollback process, the testing process is in danger of losing valuable time in unplanned remediation.
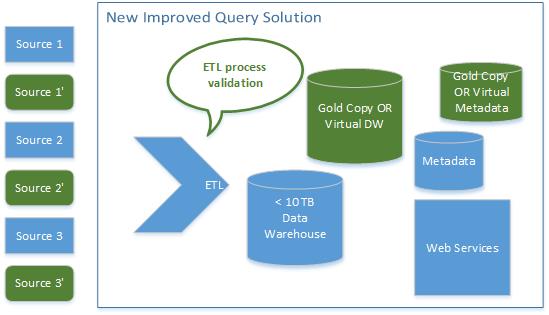
Environment and Operations Quality
The testing team should also manage and support the system under test. They should support the operations teams by helping them automate and improve the control of the environment itself. This further supports the delivery process, because it will provide a more reliable place to validate the software changes. In effect, this is a great way for the developers of the ETL code and the reporting metadata to design their solution in a safer place than production.